

This article presents a lightweight deterministic verification technique for Android applications that strengthens mobile API security without relying on heavy cryptographic exchanges. Instead of static client identifiers, the method generates dynamic verification values using the application’s APK signature and a progressing sequence. The approach enables stateless server-side validation, resists replay attacks, and avoids complex key management while remaining computationally efficient through simple byte-level operations. Its scalability and ease of integration make it suitable for large-scale Android deployments.
Mobile applications often run in environments that are only partially trusted. While the server is secure, the client device is controlled by the user, making it possible for attackers to inspect, modify, or automate the application after gaining access to the APK file. Common security methods rely on static client identifiers, such as device IDs or installation tokens. These have a major weakness: they are static and do not change. If an attacker obtains the static ID, the client can be impersonated indefinitely.
Furthermore, existing solutions often use complex cryptographic protocols that increase computational costs and are difficult to integrate. The proposed solution is based on deterministic state progression. This means the server verifies the client based on how its state changes over time, rather than checking a single fixed value.
This is particularly relevant for large-scale mobile API ecosystems where lightweight verification and operational simplicity are critical.
Threat Model and Design Goals
The system assumes an attacker can inspect the application binary, monitor traffic, and automate requests, but lacks access to server-side logic. The goal is to significantly increase the attack effort rather than achieve absolute prevention.
The design prioritizes lightweight execution for minimal device impact, deterministic behavior combined with randomness, server-verifiable state progression, and low operational cost by eliminating complex key management.
Client-Side State and Progression
The mechanism relies on a client-maintained sequence position. This position is represented as a simple integer that advances after each successful interaction. To preserve continuity across application restarts, the client stores a minimal progression indicator in local storage.
This value does not represent identity, credentials, or any sensitive attribute. It only reflects the current position within the structured sequence. The stored value has no independent security significance. Even if an attacker gains access to it, the value provides no operational advantage. If it is erased, reset, or modified, the sequence alignment between client and server is disrupted, and validation fails naturally without requiring additional defensive logic.
This approach maintains operational continuity while keeping the persisted state lightweight and non-sensitive. The sequence progresses strictly forward. The client does not attempt to re-synchronize based on server error responses, preventing state manipulation through fake or replayed error conditions.
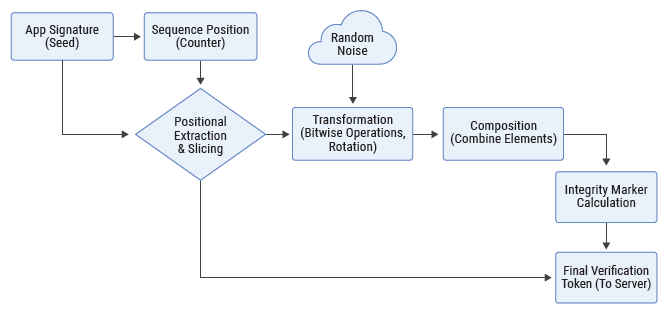 Fig: 11.1 : Client-side process
Fig: 11.1 : Client-side process
The Value Derivation Pipeline (Client)
Instead of transmitting a static identifier, the client derives a new verification value for each request using a deterministic multi-stage process.
Seed Generation
The process begins with a base seed derived from the application’s APK signature hash. This binds the mechanism to a specific build. The seed remains local and is never transmitted.
Positional Extraction
A small segment of the seed is selected based on the current sequence position. As the position advances, different segments are used, ensuring variation across requests while remaining reproducible on the server.
Transformation and Obfuscation
The selected segment undergoes bit-level transformations, such as lightweight bit-level transformations, to alter its representation. Additional non-semantic characters are inserted into the transmitted string to make structural analysis and pattern observation more difficult. These characters are ignored during verification.
Integrity Marker
A checksum is computed from the transformed segment. This enables early rejection of corrupted or tampered values before deeper validation is performed.
Server-Side Reconstruction
The server operates in a stateless manner. Upon receiving a value, the server does not attempt decryption. Instead, it reconstructs the expected result using the same reproducible process.
- Parsing: The encoded sequence position is extracted from the incoming message.
- Seed Re-computation: Using its stored copy of the application signature, the server regenerates the corresponding internal seed.
- Simulation: The server applies the identical extraction and transformation steps to derive the expected value.
- Comparison: The derived value is compared with the received value. An exact match is required.
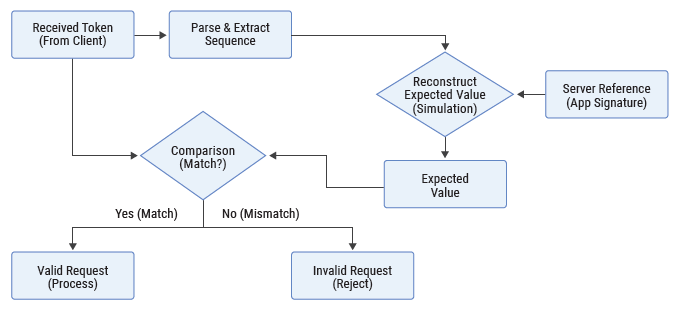 Fig: 11.2 : Server-side reconstruction
Fig: 11.2 : Server-side reconstruction
Independent Validation
Because the server recomputes the seed on demand, it never needs to store client secrets. Each request is verified independently. If a request is valid, it is accepted; otherwise, it is rejected without revealing the specific reason, such as “wrong sequence” or “bad checksum.”
Security Analysis
The proposed mechanism derives its strength from asymmetric effort.
- Client-Side Cost: The computational cost is minimal. Operations involve simple byte transformations and execute quickly on standard devices.
- Attack Effort: Forging a valid request requires replicating the complete internal derivation pipeline. Simple replay attempts are ineffective because the sequence position advances with each interaction.
- Cloning Resistance: Possession of the application binary alone is insufficient. Without authoritative server-side reference data and deterministic alignment, generated values cannot be validated.
- Uniform Failure Behaviour: All validation failures produce indistinguishable outcomes. This prevents attackers from inferring internal logic through error-based probing.
| Feature | Static Identifiers (e.g., Device ID) | Heavy Cryptography (e.g., Client Certificates) | Proposed Deterministic Method |
|---|---|---|---|
| Client Identifier | Fixed, unchanging value | Private key | Dynamic, progresses with each request |
| Replay Protection | None (easily replayed) | High (via nonces/timestamps) | Difficult due to continuously progressing verification values |
| Server State | Stateful (must store IDs) | Stateful (manages certificates/keys) | Stateless (reconstructs on demand) |
| Computational Cost | Very low | High (complex mathematical operations) | Low (bitwise operations) |
| Primary Weakness | Vulnerable to theft and replay | Complex to manage and deploy | Reverse engineering resistance depends on implementation hardening |
Operational and Deployment Benefits
From an engineering standpoint, the approach is practical for large-scale deployments.
- Constant Performance: The verification logic consists of fixed-size byte operations and runs in constant time, O(1), per request. Performance does not degrade with user growth.
- No Database Dependency: Verification does not require per-user database lookups, reducing latency and server load.
- Stateless Validation: Each request is evaluated independently, simplifying horizontal scaling.
- Offline Readiness: The client can initialize and advance its progression state without immediate network access.
- Integration Simplicity: The logic integrates into standard application workflows without specialized permissions or background services.
Conclusion
This article presents a practical deterministic verification method for strengthening trust in Android client applications without relying on heavy cryptographic exchanges. By binding verification to the application build signature and a progressing internal sequence, the technique increases the effort required for impersonation and automated abuse. Its lightweight computation, stateless server validation, and ease of deployment make it suitable for high-scale mobile environments where performance and operational simplicity are critical.
- Edited by:C. J. ANTONY
Author / Contributor

Dr. Ambati Bubli Sagar Scientist-B sagar.ambati[at]nic[dot]in
- Tag:
- Internet
- Technology
- eGov
- Tech
Dr. Ambati Bubli Sagar
Scientist-B
NIC, Andhra Pradesh State Unit, A-Block
3rd Floor, R&B Building, M.G. Road, Labbipet
Vijayawada, Andhra Pradesh – 520010


